Natural language processing as a tool to explore the information in vast bodies of literature
Summary¶
Climate change will most likely lead to an increase of extreme weather events, including heavy rainfall with soil surface runoff and erosion. Adapting agricultural management practices that lead to increased infiltration capacities of soil has potential to mitigate these risks. However, effects of agricultural management practices (tillage, cover crops, amendment, …) on soil variables (hydraulic conductivity, aggregate stability, …) often depend on the pedo-climatic context. Hence, in order to be able to advise stakeholders on suitable management practices, it is important to quantify such dependencies using meta-analyses of studies investigating this topic. As a first step, structured information from scientific publications needs to be extracted to build a meta-database, which then can be analyzed and recommendations can be given in dependence to the pedo-climatic context.
Manually building such a database by going through all publications is very time-consuming. Given the increasing amount of literature, this task is likely to require more and more effort in the future. Natural language processing (NLP) facilitates this task. In this work, two sets of documents (corpus) were used: the OTIM corpus contains the source publications of the entries of the OTIM-DB of near-saturated hydraulic conductivity from tension-disk infiltrometer measurements and the Meta corpus is constituted of all primary studies from 36 selected meta-analyses on the impact of agricultural practices on sustainable water management in Europe. We focused on three NLP techniques: i) we used of topic modelling to sort the individual source-publications of the Meta corpus into 6 topics (e.g. related to cover crops, biochar, …) with an average coherence metric Cv of 0.68; ii) we used tailored regular expressions and dictionaries to extract coordinates, soil texture, soil type, rainfall, disk diameter and tensions on the OTIM corpus. We found that the respective information could be retrieved relatively well, with 56% up to 100% relevant information retrieved with a precision between 83% and 100%; and iii) we extracted relationships between a set of “driver” keywords (e.g. ‘biochar’, ‘zero tillage’, …) and “variables”, i.e. soil and site properties (e.g. ‘soil aggregate’, ‘hydraulic conductivity’, ‘crop yield’,…) from the source-publications’ abstracts of the Meta corpus using the shortest dependency path between them. These relationships were further classified according to positive, negative or absent correlations between the driver and soil property. This latter technique quickly provided an overview of the different driver-variable relationships and their abundance for an entire body of literature. For instance, we were able to retrieve the positive correlation between biochar and crop yield as well as the negative correlation between biochar and bulk density, both of which had been independently found to be present in the investigated meta-database.
Overall, the three NLP techniques from the simplest regular expression to the more complex relationships extraction were able to support evidence synthesis tasks such as selecting relevant publications on a topic, extracting specific information to build databases for meta-analysis and providing an overview of relationships found in the corpus. While human supervision remains essential, NLP methods have the potential to support fully automated evidence synthesis that can be continuously updated as new publications become available.
Introduction¶
The effect of agricultural practices on agroecosystems is highly dependent upon other environmental factors such as climate and soil. In this context, summarizing information from scientific literature while extracting relevant environmental variables is important to establish pedo-climatic specific conclusions. This synthesis is essential to provide recommendations for soil management adaptations that are adequate for local conditions, both, today and in the future. Efforts to synthesize context-specific evidence through meta-analysis or reviews requires a lot of manual work to read respective papers and extract relevant information. This effort scales with the number of available relevant publications. In the meantime, the use of automated methods to analyze unstructured information (like text in a scientific publication) has been developing during recent years and has demonstrated potential to support evidence synthesis Haddaway , 2020. Natural language processing (NLP) is one of them. In their review on the advances of the technique, Hirschberg & Manning (2019) explained that “Natural language processing employs computational techniques for the purpose of learning, understanding, and producing human language content.” This definition is quite broad as NLP encompasses several considerably different techniques, like machine translation, information extraction or natural language understanding. Nadkarni (2011) and Hirschberg & Manning (2019) provide a good overview on this field of research and how it originally developed. For applications to scientific publications, Nasar (2018) reviewed different NLP techniques (information extraction, recommender systems, classification and clustering and summarizations). However, one limitation of supervised NLP techniques is that they require labels that need to be manually produced to train the model. Hence, humans are still needed for evidence synthesis but can certainly receive great support from existing NLP techniques.
NLP methods are most widely used in medical research. The development of electronic health records significantly facilitated the application of automatic methods to extract information in this field of research. For instance, information extraction techniques were used to identify adverse reactions to drugs, identify patients with certain illnesses which were not discovered yet at the time or link genes with their respective expression Wang , 2018. A specific example is given by Tao (2017) who used word embedding and controlled random fields to extract prescriptions from discharge summaries. Wang (2018) provide an extensive review of the use of NLP for the medical context.
The rise of open-source software tools such as NLTK Loper & Bird, 2002 and SpaCy Honnibal & Montani, 2017 together with the increase in digitally available information has fostered the way for NLP applications to other scientific communities. For example, SpaCy is able to automatically separate the words of a sentence (word segmentation) but also recognize their nature and dependence on other words using a combination of rules-based and statistical methods. In the context of information extraction too, open-source tools exist also in the context of information extraction. A very popular tool is the OpenIE framework of the Stanford group Angeli , 2015 included in the Stanford coreNLP package Manning , 2014. Niklaus (2018) present a review of open information extraction codes. All these tools greatly reduce the knowledge required to start using NLP technique and therefore supports NLP applications.
In the context of evidence synthesis, several NLP methods can be useful. Topic modeling can help group publications which are on the same topic but also assign a new publication to a given topic. In addition to selecting publications to be reviewed in the evidence synthesis , this also gives an overview of the number of publications per topic and potentially can help to identify knowledge gaps. Regular expressions search the text for a pattern of predefined numbers and words. They have a high precision but only find what they are designed to find. They can be augmented by including syntaxic information such as the nature (noun, adjective, adverb, …) and function (verb, subject, …) of a word. Complemented with dictionaries that contain lists of specific words (e.g. WRB soil groups), it can be a powerful method. More advanced NLP techniques aim at transforming words into numerical representations that can be further processed by numerical machine learning algorithms. For instance, word embedding are vectors which encode information about a word and its linguistic relationships in the context it is found. They are derived from the corpus of documents available. Another advanced technique for doing such conversion include transformer networks such as BERT which is a deep learning neural network that converts text to a numerical representation Koroteev, 2021. BERT transformers are trained on specific corpus. For instance bioBERT is tailored to the medical context Lee , 2020.
In contrast to the medical context, fewer studies applied NLP methods to soil sciences. Padarian (2020) used topic modeling in their review of the use of machine learning in soil sciences. Furey (2019) presented NLP methods to extract pedological information from soil survey description. Padarian & Fuentes (2019) used word embedding. Using the multi-dimensional vectors (=embedding), they were able to establish relationships between soil type and other words through principal component analysis. For instance, ‘Vertisols’ were associated with ‘cracks’ or ‘Andosols’ with volcanoes as their embeddings were similar.
The novelty of work lies in applying NLP technique to soil science publications for evidence synthesis. This manuscript is not foreseen to demonstrate the latest and most advanced NLP techniques but rather to offer a practical view and demonstrate their potentials and limitations in a soil scientific context. We put special emphasis on the methodology used and its ability to recover information rather than interpreting the results themselves. We redirect the reader to chapters 1, 2 and 3 for detailed interpretation of the evidence synthesis. Overall, the objectives of this paper are (1) to demonstrate the potential of natural language processing as for the collection of structured information from scientific publication, (2) to illustrate the ability of topic classification to classify new paper as relevant to a given topic and (3) to assess the ability of natural language processing to extract relationships between given driver (tillage, cover crops, amendment, …) and soil variables (hydraulic conductivity, aggregate stability, …) based on abstracts.
Materials and methods¶
Text corpora¶
This work used two corpora (sets of texts) which are referred to in the following as the OTIM and the Meta corpuses. The OTIM corpus is related to OTIM-DB (Koestel et al., in prep) which is a meta-database extending the one analyzed in Jarvis (2013) and Jorda (2015). OTIM-DB contains information about the near-saturated hydraulic conductivity obtained from tension-disk infiltrometer between 0 and -10 cm tension (see Koestel et al., in prep. for more information). The meta-database also includes metadata on the soil (texture, bulk density, organic carbon content, WRB classification), 23 climatic variables that were assigned based on the coordinates of the measurement locations, among them annual mean temperature and precipitation, methodological setup (disk diameter, method with which infiltration data is converted to hydraulic conductivity, month of measurement) and land management practices (land use, tillage, cover crops, crop rotation, irrigation, compaction). All data in OTIM-DB were manually extracted by researchers from 172 source-publications. The collected data was then cross-checked by another researcher to catch typos and misinterpretations of the published information. The Meta corpus contained the abstracts of primary studies included in the meta-analyses by Jarvis et al., (in prep.) investigating how soil water infiltration is influenced by soil management practices This Meta corpus contains 1469 publications and hence is larger than the OTIM corpus. The information given in this corpus was not available in a meta-database. Therefore, the validation step had to be carried out by manually extracting information from a subset of the abstracts in this corpus. The references for both, the OTIM and the Meta corpus are available on the GitHub repository of this project.
Extracting plain text from the PDF format¶
For both corpora, all publications were retrieved as PDF files. The software “pdftotext” (https://www.xpdfreader.com/pdftotext-man.html) was used to extract the text from these PDFs. The text extraction worked well apart from one exception where the extracted text contained alternating sentences from two different text columns, making it unsuited for NLP. Other methods were tested, such as the use of the Python package PyPDF2 or the use of the framework pdf.js but did not provide better results than pdftotext. The difficulty of this conversion lies in the PDF format itself that locates words in reference to the page and hence loses the fact that words form sentences and paragraphs. Recovery methods (such in pdf.js or pdftotext) use the distance between words to infer if they belong to the same sentence and detect paragraphs. This makes extracting text from PDF harder for algorithms and is clearly a major drawback of this format. This could be potentially alleviated by using online full-text HTML as source instead of PDF. However, because online HTML full-texts were not available for all documents and the PDF format is the most widespread for exchanging scientific publication, we decided to pursue the analysis with the PDF formats. From the extracted full-texts, abstract and references sections were removed and only the body of the text was used to form the documents for each corpus.
Topic modeling¶
Topic modeling creates topics from a corpus by comparing the similarity of the words between documents. In this study, each document was composed of bigrams (groups of two words that appear consecutively more than 20 times in the document). We found that using bigrams instead of single words help to get more coherent topics. For instance, the bigrams ‘cover crops’, ‘conventional tillage’ are more informative than ‘cover’, ‘crops’, ‘conventional’ and ‘tillage’ alone. Bigrams that appeared in more than 20 documents but in less than 50% of documents were kept. Topics were created to be as coherent as possible using a latent dirichlet algorithm (LDA). A number of different coherence metrics exist Röder (2015). In this work, the LDA implementation of the gensim library (v4.1.2) was used with the CV coherence metric. This CV coherence metric is a combination of a normalized pointwise mutual information coherence measure, cosine vector similarity and a boolean sliding window of size 110 as defined in Röder (2015). The metric ranges from 0 (not coherent at all) to 1 (fully coherent). To define the optimal number of topics to be modeled, we iteratively increase the number of topics from 2 to 30 and look at the averaged topic coherence. Based on this optimal number of topics, the composition of each topic was further analyzed using the pyLDAvis package (v3.3.1) which is based upon the work of Sievert & Shirley (2014). The topic modeling was applied on the Meta corpus given the larger number of documents in this corpus.
Rules-based extraction¶
Regular expressions are predefined patterns that can include text, number and symbols. For instance, if we are looking for the disk-diameter of the tension-disk infiltrometer, the regular expression ‘(\d+\.\d)cm\sdiameter’ will match ‘5.4 cm diameter’. In this regular expression, \d means a digit, \s a space, \d+ one or more digit and parentheses are used to enclose the group we want to extract. Regular expressions are a widely used rule-based extraction tool in computer science. They have a high precision but their complexity can quickly increase for more specific topics. Figure 1 provides examples of regular expressions used in this work. It can be observed that regular expressions for geographic coordinates are quite complex as they need to account for different scenarios such as decimal format (24.534 N) or degree-minute-second format (24°4’23.03'' N) for instance. In contrast, specific well-defined terms such as World Reference Base (WRB) soil types were easier to retrieve as their wording is unique in the text. Soil textures were likewise easy to extract but less well-defined as e.g. WRB soil types. Often, terms used to describe soil texture of an investigated field site were used to refer to general cases or unrelated field sites in the same text. This made it more challenging to automatically extract information on the investigated site using regular expressions. To complicate matters, soil textures are not always given in the USDA (United States Department of Agriculture) classification system, which can be regarded as a standard for soil. For the sake of simplicity, we did not attempt to identify the texture classification system but treated all textural information as if they were using the USDA system. When gathering information on tension-disk diameters, attention on the length units needed to be paid as well as whether the radius or the diameter is reported. In these more complex cases, the regular expressions were iteratively modified to extract the greatest amount of information from the available papers. For tensions applied, only the maximum tension recovered was used to compute the metrics.

Examples of different regular expressions used for information extraction. \d represents a digit, \s a space, . (a dot) an unspecified character, [a-z] all lower case letters and more generally squared brackets are used to denote the list of characters (for e.g. [°*o0] is used to catch the symbol of degree in latitude/longitude). A character can be “present once or absent” (\d\.?\d? will match both integers and decimal numbers), “present at least once” (\d+ will match 7, 73 and 735) or “present a given number of times” (\d{1,2} will match 7 and 73 but not 735). Parentheses are used to segment capturing groups and can also contains boolean operator such as OR denoted by | which is used to catch exact WRB soil name in (Luvisol | Cambisol | …). Non-capturing parentheses are denoted with (?:) like for the regular expression of tensions. The content inside non-capturing parentheses will not be outputted as results of the regular expression in contrast to other parenthesis groups.
To assess the quality of the extraction, different metrics were used (Figure 2). For rules-based extraction, two tasks were required by the algorithm: selection and matching. The selection task aimed to assess the ability of the algorithm to extract relevant information from the text. The matching task assessed the ability of the algorithm to extract not only the relevant, but also the correct specific information as recorded in the database used for validation. For instance, if the NLP algorithm identified “Cambisol” as the soil group for a study conducted on a Cambisol, both, the selection was true positive (TP) and the matching was true. If the text did not contain any WRB soil type and the NLP did not return any, both selection and matching performed well with the selection being a true negative (TN) case. Eventually, when the NLP algorithm did not find a WRB soil type, but the database listed one, the selection was referred to as false negative (FN) and the matching as false. The opposite case, with a soil type found in the text but no entry in the database was called false positive (FP) and the matching was equally false. Eventually, there were cases where the NLP algorithm retrieved incorrect information but still provided a meaningful value, e.g. if the algorithm extracted ‘Luvisol’ as the soil type while the correct value was ‘Cambisol’. Then the selection task was still successful since the found term represents a WRB soil type. However, the matching task failed. Such cases were still marked as false positives, but with a false matching.
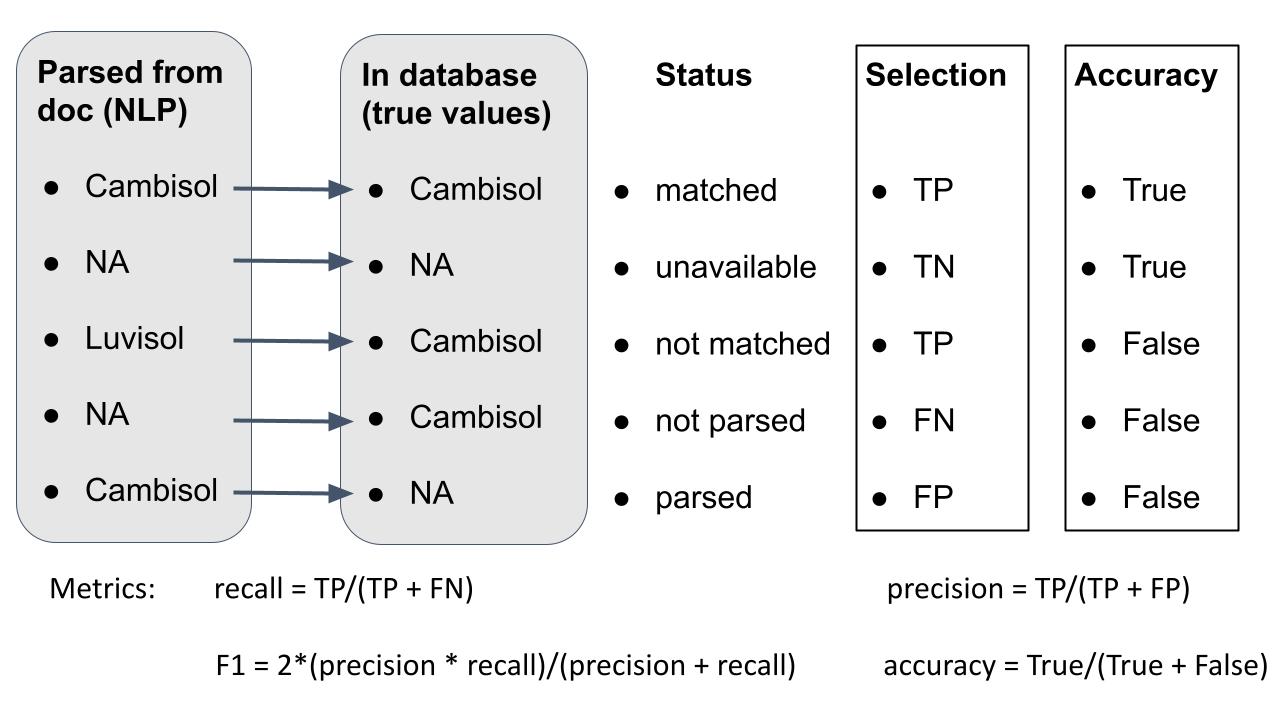
Cases of NLP extraction results in regards to the value entered in the database (considered the correct values) for the selection task and the matching task. TP, TN, FN, FP stand for true positive, true negative, false negative and false positive, respectively. The recall, precision, F1 score and accuracy values served as metrics for each task.
Four different metrics were used to evaluate the results: the recall, the precision, the F1 score and the accuracy. The recall assessed the ability of the algorithm to find all relevant words in the corpus (recall = 1). The precision assessed the ability of the algorithm to only select relevant words (precision = 1). If there were 100 soil types to be found in the corpus and the algorithm retrieved 80 words of which 40 were actually soil types, the recall was 40/100 = 0.4 and the precision was 40/80 = 0.5. The F1 score brought the recall and precision in one metric which was equal to 1 if both recall and precision were equal to 1.The recall, precision and F1 scores were used to assess the ability of the algorithm to extract relevant information from the text. Figure 3 gives a graphical overview of the recall and precision metrics. In addition to these metrics, an accuracy score was used to illustrate how many NLP extracted values actually matched the one manually entered in the database. Considering the example above, if out of the 40 correctly selected soil types, only 20 actually matched what was labeled in the document, then the accuracy score was 20/100 = 0.2. Figure 3 also includes the equations for recall, precision, F1 score and accuracy. Note the difference between precision and accuracy: the precision expresses how many relevant words were extracted while the accuracy quantifies the fraction of words corresponding to the correct information.
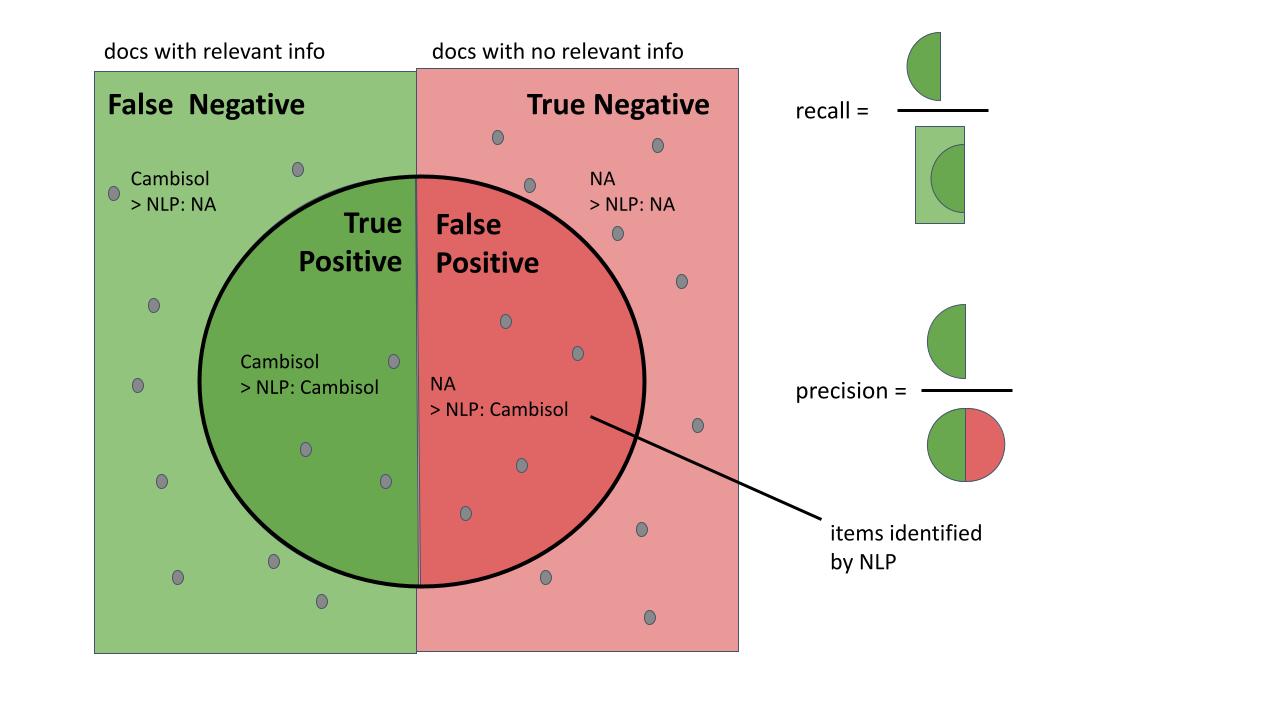
Schematic representation of precision and recall. Recall aims to assess how much relevant information was selected out of all the ones available in the database while precision aims to assess how much relevant information was in the selection.
All rules-based extraction were applied on the OTIM corpus as information from the OTIM-DB was used for validation. In addition to the above extraction rules, we also identified agricultural practices mentioned in the publications and their co-occurrence within the same publications. This enabled us to highlight which practices are often found together in a study (whether they are opposed or not). To identify management practices in the OTIM corpus, the list of keywords from the Bonares Knowledge Library (https://klibrary.bonares.de/soildoc/soil-doc-search). Given that several keywords can relate to the same practice, the list was further expanded by using the synonyms available from the FAO thesaurus AGROVOC Caracciolo , 2013.
Extracting relationships¶
Relationship extraction relates drivers defined by specific key terms to variables. For both drivers and variables. In this study, examples for drivers were 'tillage', 'cover crop', or ‘irrigation’. Among the investigated variables were ‘hydraulic conductivity’, ‘water retention’ or ‘runoff’. These keywords were chosen to correspond to the initial search done to build the Meta corpus (WP3T1). To allow catching both plural and singular form, all drivers and keywords were converted to their meaningful root: their lemma (e.g. ‘residues’ lemma is ‘residue’). Table 1 lists the lemma of all drivers and variables considered.
List of drivers and variables used in the relationships extraction.
Drivers | Variables |
|---|---|
agroforestry biochar catch crop compaction cover crop fertilizer intercropping irrigation liming compost manure residue tillage traffic | aggregate stability aggregation available water bulk density earthworm activity earthworm biomass faunal activity faunal biomass hydraulic conductivity infiltration infiltration rate K K(h) K0 Ks macroporosity microbial activity microbial biomass organic carbon organic matter penetration resistance rainwater penetration root biomass root depth root growth runoff soil strength water retention yield |
The relationship extraction algorithm searched in the Meta corpus of abstracts for sentences which contained lemmas of both, drivers and variables. Each sentence was then tokenized and each token was assigned a part-of-speech (POS) tag (e.g. noun, verb, adjective). Dependencies between the tokens were also computed. Using these dependencies as links, a graph with one node per token was built. The nodes corresponding to the driver and variables were identified and the shortest dependency path between them was computed (Figure 4).
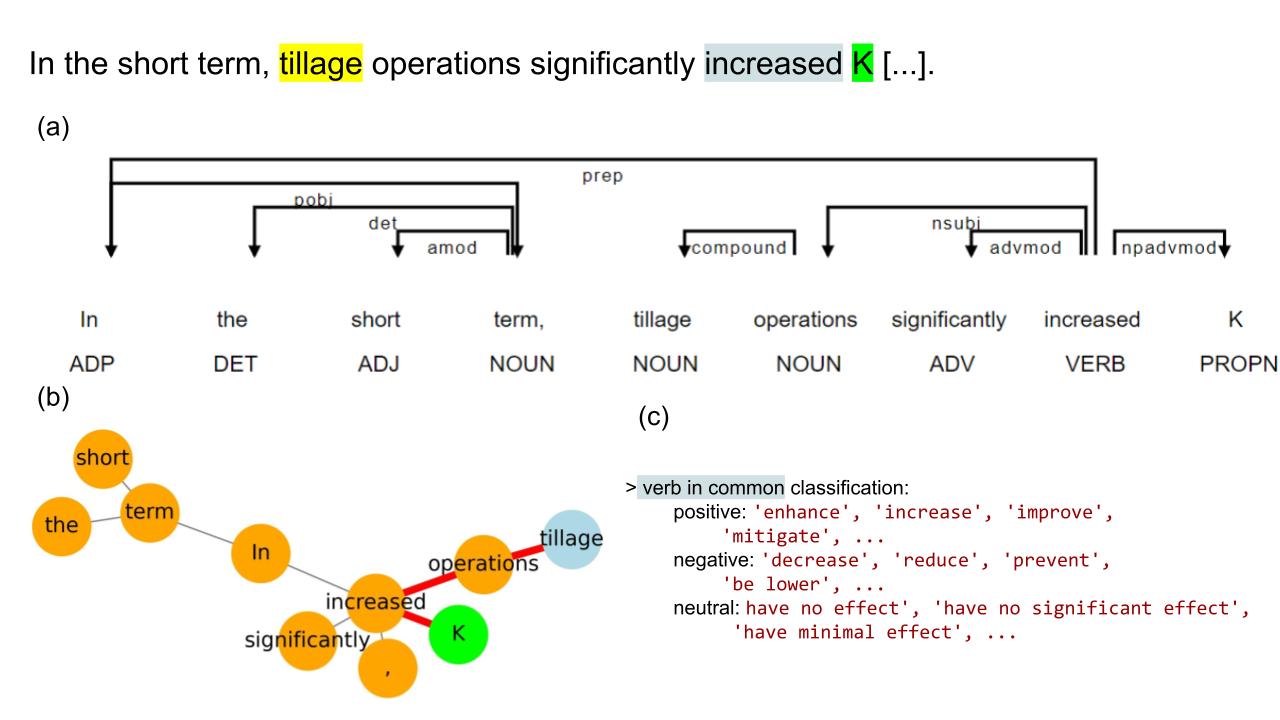
Example of NLP extraction on a sentence. (a) shows the part-of-speech (POS) tag below each token and the dependencies (arrows) to other tokens. (b) based on these dependencies a network graph was created and the shortest dependency path between the driver (blue circle) and the variable (green circle) is shown in red. (c) The verb contained in the shortest dependency path was classified into positive, negative or neutral according to pre-established lists.
All tokens that were part of this shortest dependency path between the driver token and the variable token were kept in a list. From this list, the tokens containing the driver/variables were replaced by the noun chunk (=groups of nouns and adjectives around the token) as important information can be contained in this chunk. For instance the driver token “tillage” was replaced by its noun chunk “conventional tillage”. The list of tokens that constituted the shortest dependency path always included the main verb linking the driver and the variable token. This verb depicted a positive, negative or neutral correlation between the driver and the variable. Other modifiers such as negation marks or other modifiers that can be part of the noun chunk (e.g. ‘conservation’ or ‘conventional’ with the noun ‘tillage’) were also searched for in each sentence. In cases where a positive correlation was negated (e.g. “did not increase”, “did not have significant effect on”), the relationship was classified as neutral. Sometimes, the relationship did not relate directly to the correlation between the driver and the variable but rather mention that this relationship was studied in the manuscript. Then, the status of the relationships was set to “study”. To assess the recall and precision of the technique, a subset of 129 relationships extracted was manually labeled.
Examples of relationships identified and their corresponding classified labels. Note that the modifiers present in the noun chunk (e.g. “conservation tillage” or “zero tillage”) and the negation in the sentence were taken into account in the status of the relationship. Some sentences contain multiple driver/variable pairs and, hence, multiple relationships. In such cases, only one of the two was indicated in the table.
Relationship (driver/variable in bold) | Status |
|---|---|
In the short term, tillage operations significantly increased K (P < 0.05) for the entire range of pressure head applied [...]. | positive |
In humid areas, soil compaction might increase the risk of surface runoff and erosion due to decreased rainwater infiltration. | positive |
Both tillage treatments were designed to prevent runoff and both increased rainwater penetration of the soil. | negative |
After 3 years of continuous tillage treatments, the soil bulk density did not increase. | neutral |
No-tillage increased water conducting macropores but did not increase hydraulic conductivity irrespective of slope position. | neutral |
A field study was conducted to determine the effect of tillage-residue management on earthworm development of macropore structure and the infiltration properties of a silt loam soil cropped in continuous corn. | study |
Dry bulk density , saturated hydraulic conductivity (Ks) and infiltration rate [K(h)] were analysed in untrafficked and trafficked areas in each plot. | study |
When identifying driver and variable pairs among abstracts, the case can be encountered where one of the driver/variable is expressed using a pronoun. This makes our keyword-based detection useless. The neuralcoref Python package was used to replace the pronouns by their initial form using co-reference. This package uses neural networks to establish a link between the pronoun and the entity it refers to. the pronoun is then replaced by the full text corresponding to the entity. For the Meta corpus, the co-reference substitution did not enable to increase the amount of relevant sentences extracted. It was found that it was because the use of pronouns in the respective abstracts was very limited compared to the full text body of the publications. In addition, the accuracy of the co-reference substitution was not always relevant and substitution errors were more frequent than desired. For these reasons, this step was not applied in the final processing pipeline but it is recognized that this step can be useful for other types of corpora. Automatic relationships extraction using OpenIE was also tried but given the specificity of the vocabulary in the corpus of abstract gave relatively poor prediction.
To ensure reproducibility, all codes used in this project were written down in a Jupyter Notebook. This enabled the results to be replicated and the code to be reused for other applications. The Jupyter Notebook also enabled figures and comments to be placed directly inside the document, hence helping the reader to better understand the code snippets. All notebooks used in this work are available on GitHub https://github.com/climasoma/nlp/.
Results¶
Topic modeling¶
Figure 5 shows the evolution of the coherence metric with respect to the number of topics. The averaged topic coherence increases up to 6 topics then slowly starts to decrease.
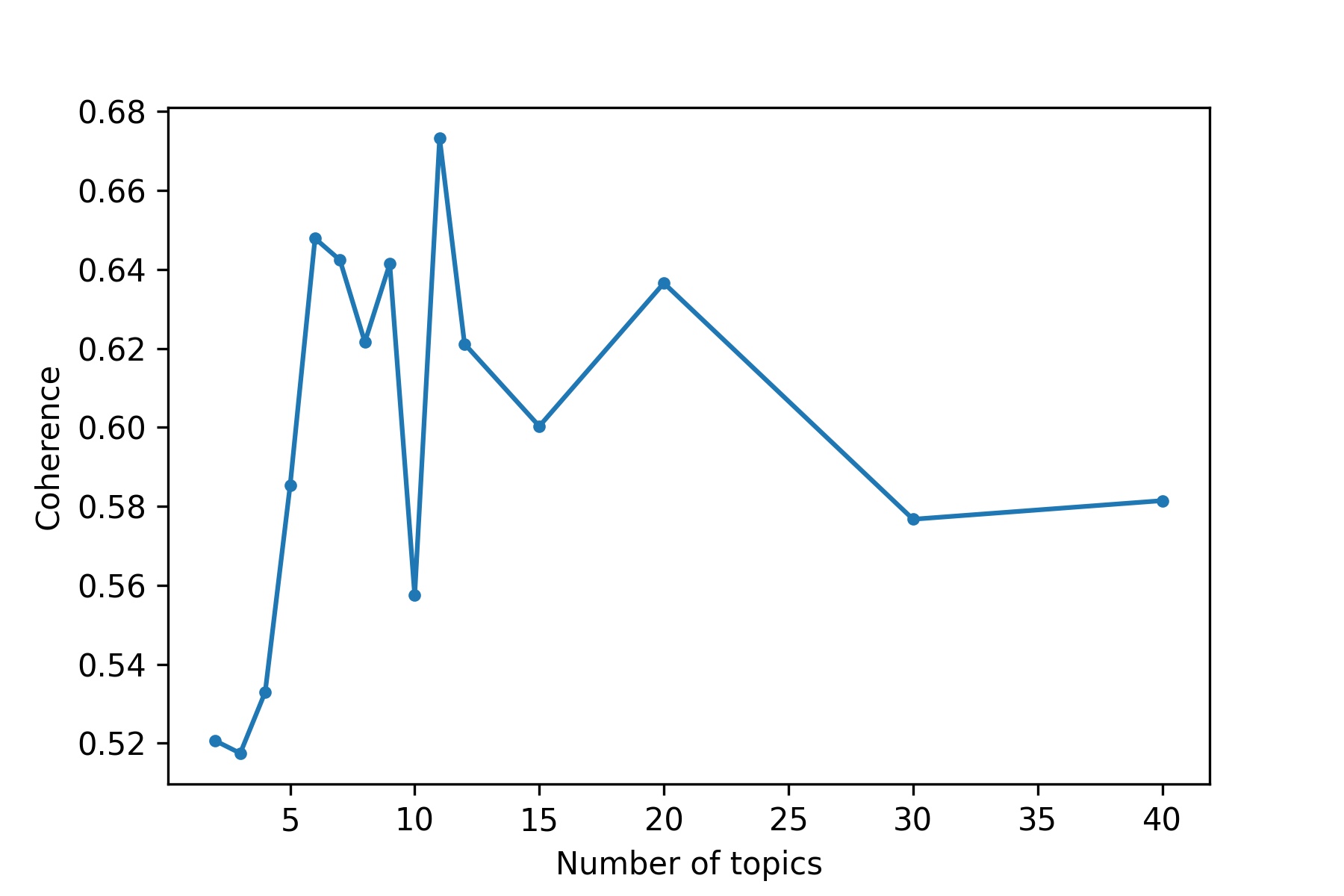
Evolution of the averaged topic coherence according to the number of topics chosen to train the LDA model. The coherence metrics is the CV described in Röder et al. (2015) which is a combination of a normalized pointwise mutual information coherence measure, cosine vector similarity and a boolean sliding window of size 110. The error bars represent the standard error of the mean.
Figure 6 (left) shows the frequency of the topic in the corpus (as percentage of documents in the corpus that belong to this topic). The circles are placed according to the first two principal components based on their inter-topic distance computed using the Jensen–Shannon divergence (Lin, 1991). Topics closer to each other are more similar than topics further apart. Figure 6 (right) shows the frequency of each bigram in the topic and in the corpus. Topic 1, 3 and 5 were relatively similar and focus mainly on cover crops, residues and conventional tillage. Topic 2 grouped papers that investigated the effect of biochar on water content and microbial biomass. Topic 4 focused on the impact of tillage on aggregate sizes. Topic 6 made mention of meta-analysis studies (though all considered documents were primary studies, not meta-analysis). The left part of Figure 6, clearly shows how Topic 1, 3 and 5 were closer to each other and how Topic 4 was away from the group according to PC2.
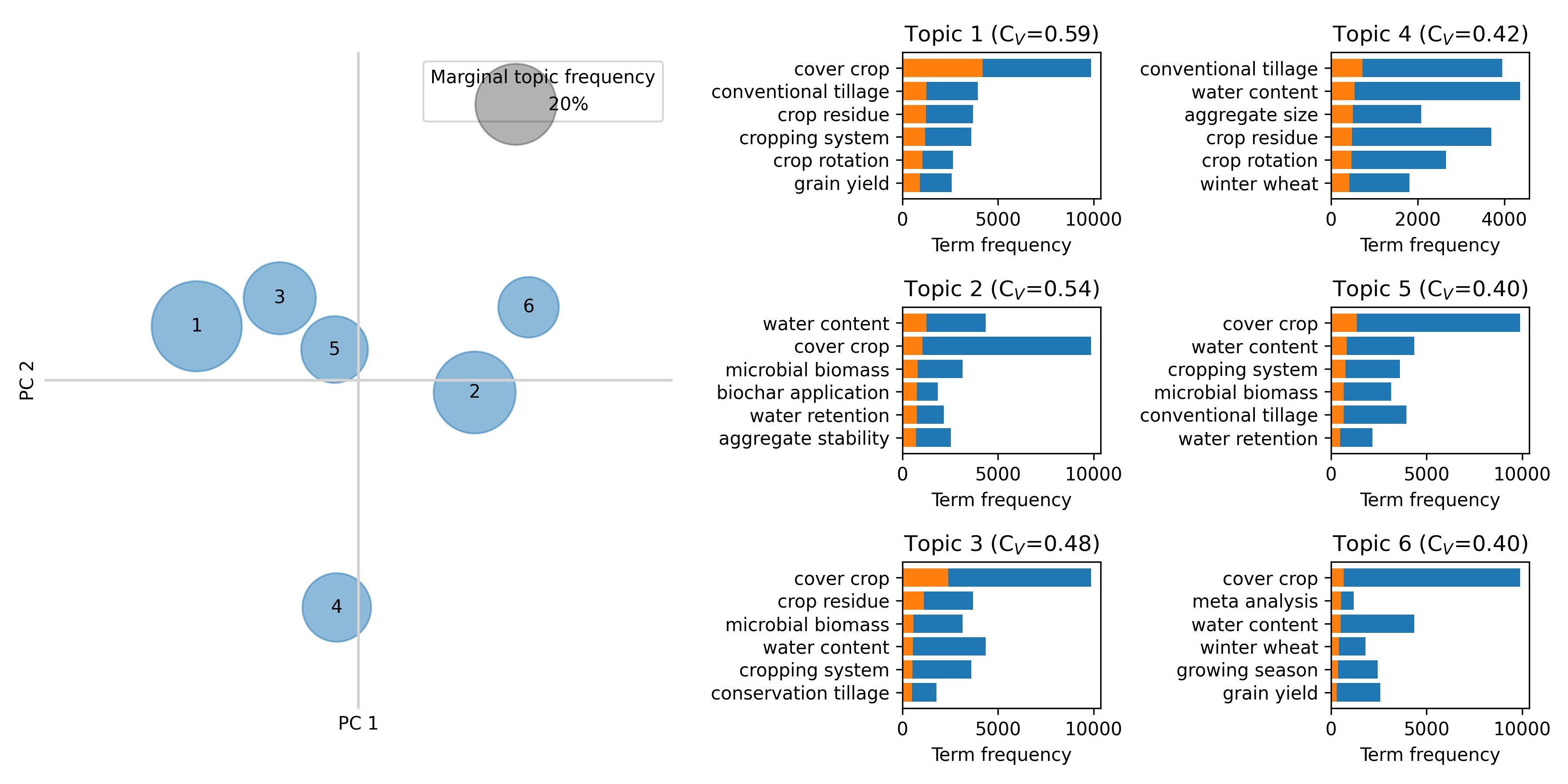
(left) Map of topics according to the first two principal components after dimension reduction. (right) For each topic, the 6 more relevant bigrams inside the topic. The orange bars represent the word frequency inside the topic while the length of the full bars (orange + blue) represent the word frequency in the entire corpus. The grey circle represents the size of a topic that contains 20% of the documents of the corpus.
Rules-based extraction¶
Table 3 shows the metrics relative to the different rules-based extraction techniques. Note that “n” does not always represent the number of documents in the corpus as a document can contain multiple locations for instance. Regular expressions associated with a dictionary for soil texture and soil type provided one of the best precision overall due to their high specificity. Soil type had the highest recall, which means that all instances of soil types mentioned in the document had been successfully extracted. Regular expression matching quantities such as ‘rainfall’, ‘disk diameter’, ‘tensions’ or ‘coordinates’ had lower recall than rules making use of a dictionary. Coordinates had a high precision but a lower recall as some coordinate format could not be extracted from the text. This could be partly explained by the conversion of the symbols for degree, minute, seconds from PDF to text. As the encoding of these characters varies a lot between journals, the conversion sometimes led to “°” converted to “O”, “*” or “0”. Identifying all these different cases while retaining a high accuracy on more frequent cases was challenging with regular expressions.
Scores of the rules-based extraction methods. n is the number of items to be extracted. It varies as several coordinates can be provided in the same paper. The method can use only a regular expression (regex) or a combination of regular expression and dictionary (regex + dict.).
Extracted | Method | n | Precision | Recall | F1-score | Accuracy |
|---|---|---|---|---|---|---|
Soil type (WRB/USDA) | Regex + dict. | 174 | 0.92 | 1.00 | 0.96 | 0.95 |
Soil texture (USDA) | Regex + dict. | 174 | 0.95 | 0.88 | 0.91 | 0.83 |
Rainfall | Regex | 174 | 1.00 | 0.81 | 0.90 | 0.89 |
Disk diameter | Regex | 174 | 0.83 | 0.66 | 0.73 | 0.41 |
Tensions | Regex | 154 | 1.00 | 0.56 | 0.72 | 0.31 |
Coordinates | Regex | 209 | 0.92 | 0.77 | 0.84 | 0.73 |
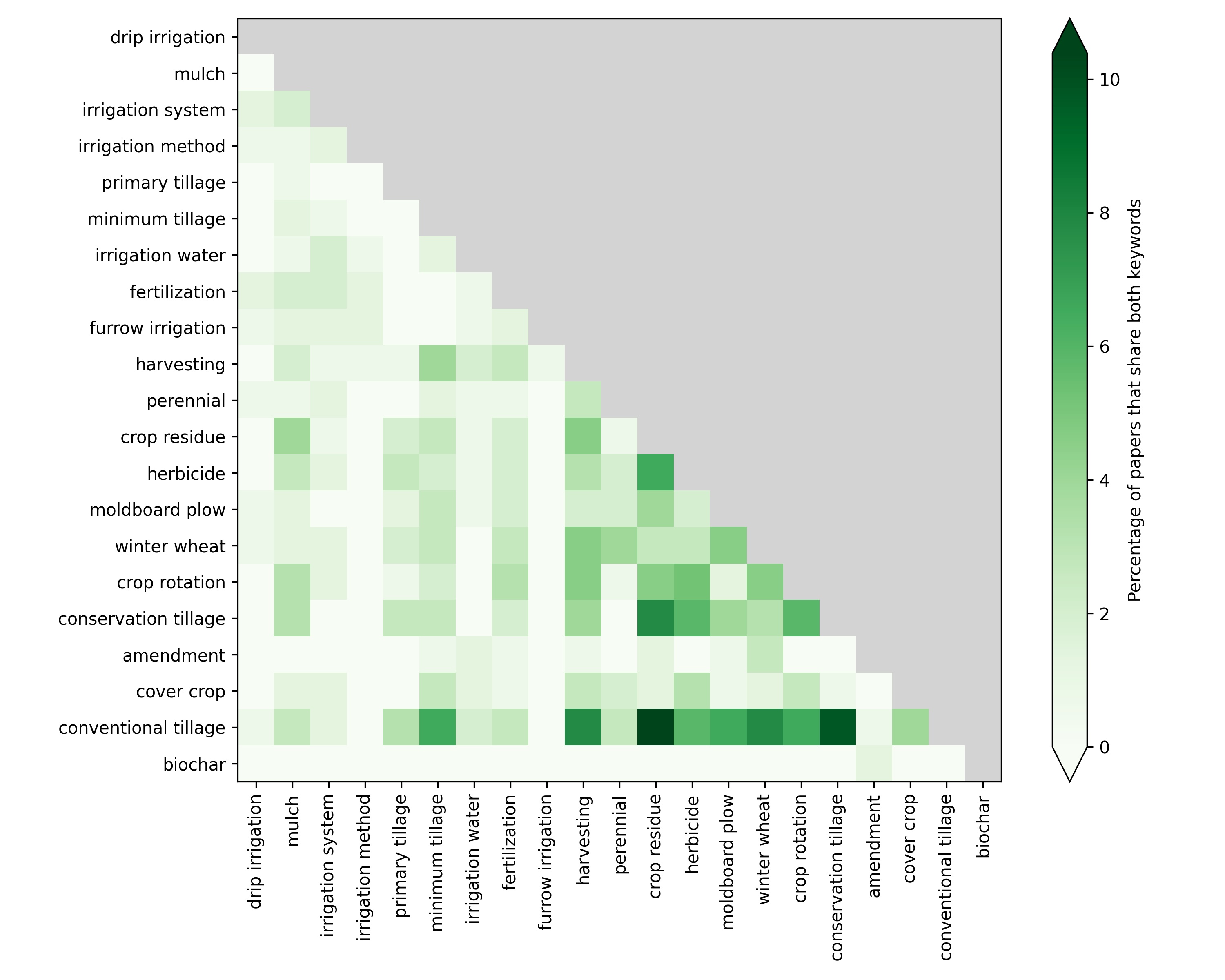
In addition to extracting specific data, general information about which management practices are investigated in the studies is also important. Figure 7 shows the co-occurrence of the detected practices inside the same document as the percentage of documents in the OTIM corpus that contains both practices. For instance, the practice of 'crop residue’ and ‘conversion tillage’ is often found with documents that contain ‘conventional tillage’. ‘herbicide’ is also often mentioned with documents containing ‘crop residue’. Given the small size of the chosen corpus, the co-occurrences are only relevant to the specific field from which they have been extracted; in this case experiments reporting unsaturated hydraulic conductivity from tension-infiltrometer.
Relationship extraction¶
Figure 8 shows the number of relationships from abstracts extracted according to the pair driver/variable identified within them. Relationships including “biochar” or “tillage” as drivers were the most frequent while “yield” was the variable commonly found. Note as well as for some combination of drivers/variables, no statements were available. This helps to identify knowledge gaps within our corpus.
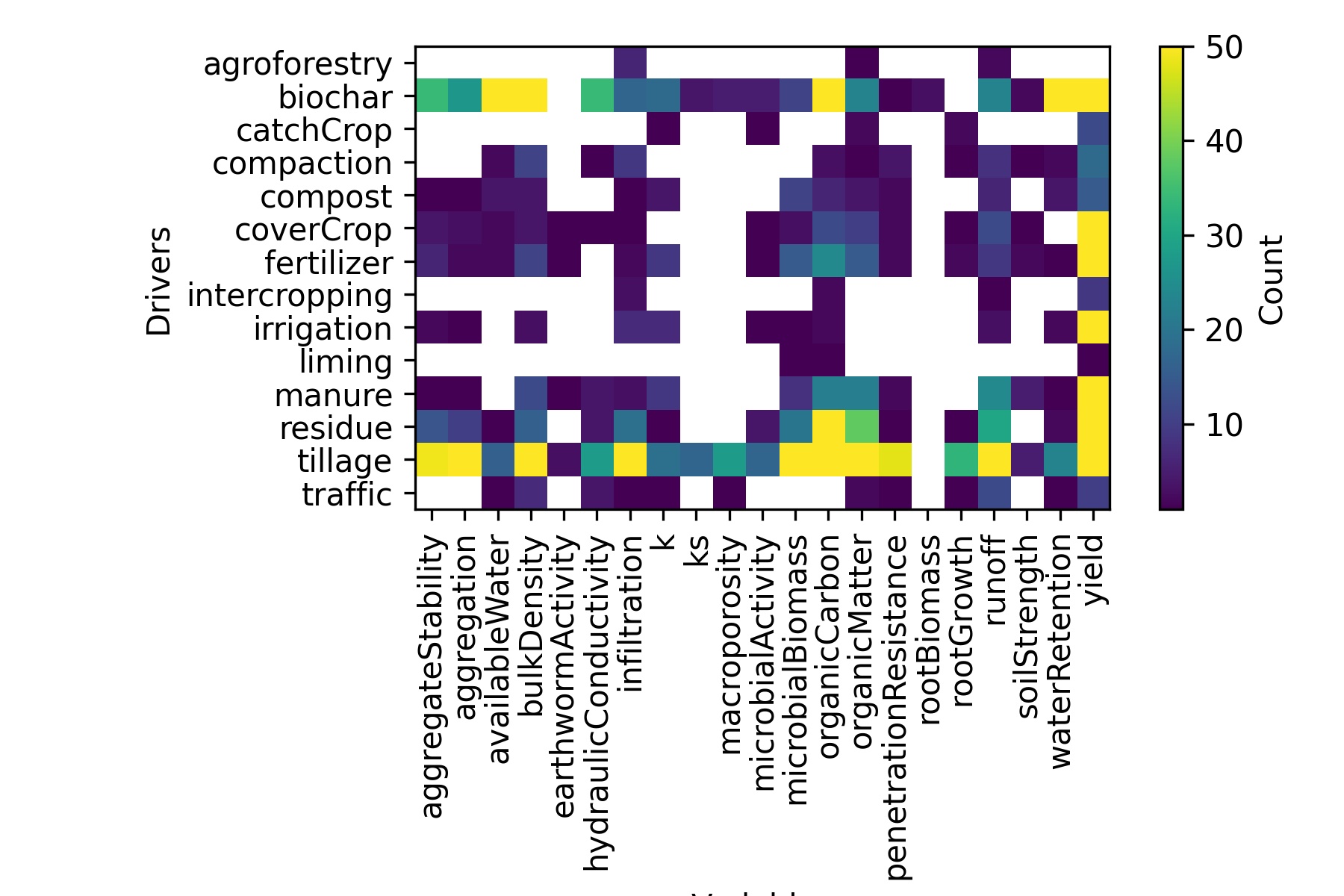
Number of relationships identified from abstract according to the pair driver/variable they contain. White cells mean that no relationships were found for the pair inside. Results obtained from the analysis on the Meta corpus.
shows the recall and the precision of the extracted relationships according to their labeled status. For each category (negative, neutral, positive or study), the dark color represents the proportion of relationships correctly identified by the NLP algorithm. The faded color represents the relationships wrongly classified by the NLP or not found at all. Overall, most identified relationships belong to the “study” class. Note as well the larger amount of “positive” relationships compared to “negative” which may be a manifestation of some bias in reporting positive results or at least writing them as positive relationships. The precision of the NLP algorithm is rather high to identify “negative” (precision = 0.99) or “study” (precision = 1.00) classes. In terms of recall, the highest score is achieved for both “positive” and “study” categories.
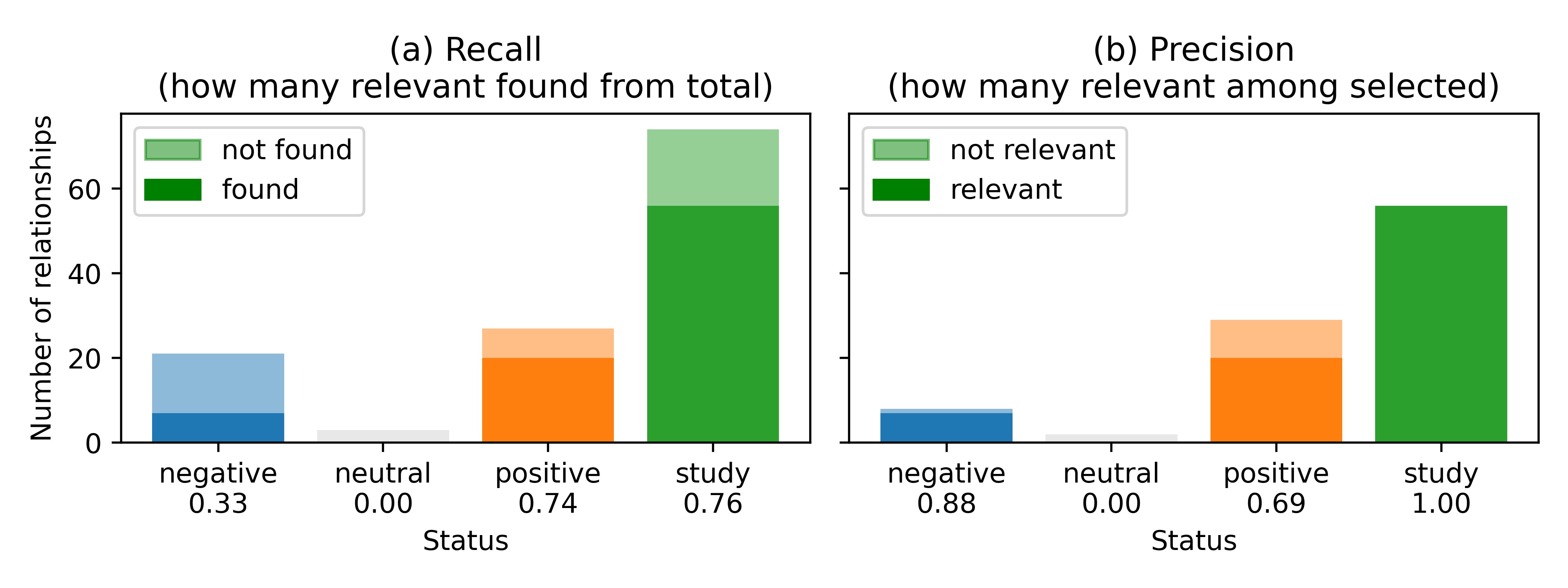
Recall (a) and precision (b) of classified relationships extracted from abstracts. Dark color represents the proportion of relationships correctly classified while the faded color represents relationships not found or not correctly classified. The recall and precision metric for each category is given on the X axis. Results obtained on the Meta corpus.
Based on manually labeled relationships and the ones recovered from NLP, Figure 10a offers a detailed comparison according to the number of statements recovered (size of the bubble) and their correlations (colors). Such a figure has the potential to be used to get a quick idea of the relationships present in a large corpus of studies (e.g. for evidence synthesis). It is also comparable to Figure 3 of Chapter 1 which presents a similar layout with the results from the selected meta-analysis. Note that for a given pair of driver/variable, not all statements have the same relationships and the bubble can contain multiple colors (e.g. biochar/yield, tillage/runoff). Compost is positively correlated to yield, residue is positively associated with lower bulk density and lower run-off, or biochar is negatively correlated to bulk density and positively correlated to microbial biomass. Most of these relationships correspond relatively well to what is reported in meta-analysis (Jarvis et al. in prep.). As demonstrated already in Figure 8, the NLP does not recover all relationships perfectly (low recall for negative relationships) and can sometimes be completely wrong (e.g. residue/bulk density). But in two thirds of cases (66%), the relationships are correctly classified.
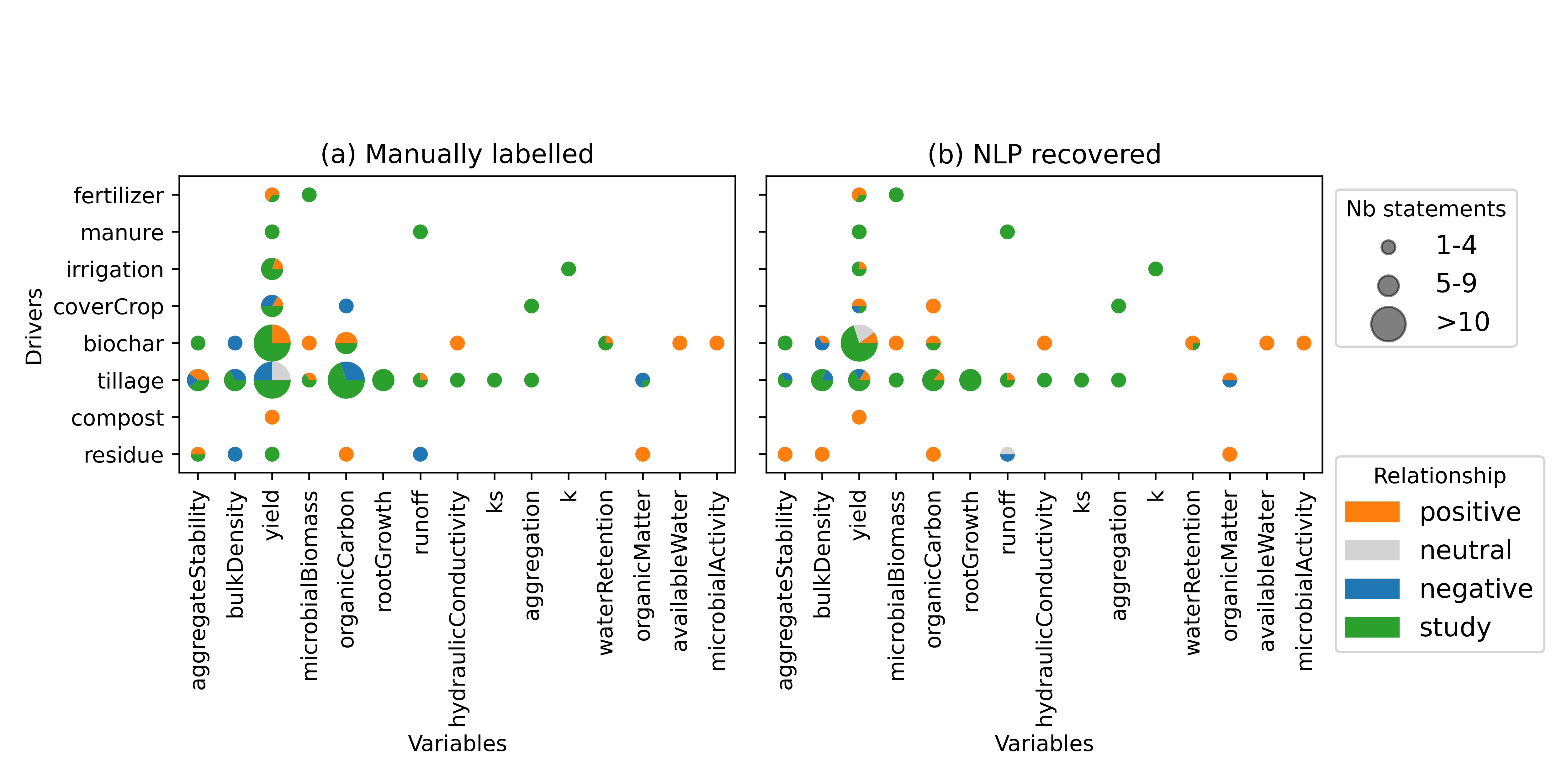
Relationships between drivers and variables as (a) manually labelled and (b) recovered by NLP for the Meta corpus.
Discussion¶
Topic modeling¶
One of the first steps of evidence synthesis is to select documents relevant to a given topic. This document selection is usually manually done based on publication title and abstracts. Starting from a first set of documents, a topic model can be used and then further applied on newer publications to see if they could belong to the same topic. Another application of topic modeling is to visualize a pool of research themes within the same topic. In this work, topic modeling was applied to the Meta corpus which contains studies from meta-analysis related to water infiltration and agricultural management practices. Topic modeling helped to identify subtopics within this corpus (Figure 6), often related to specific combinations of driver/variables (Figure 8 and Figure 10). Identifying topics and their frequency within the corpus can also give us information about knowledge gaps or areas less researched.
Rules-based extraction¶
The NLP methods presented in this paper do not aim at replacing human intervention but rather at supporting them in the repetitive tasks of information extraction from scientific publications. Regular expressions are well suited for this purpose (Table 3). While they rarely provide a 100% recall or precision, they can be used to quickly scan a large body of literature and provide a first collection of structured information that can later be manually expanded. However, regular expression needs to be built to be flexible enough to accomodate the various formats found in the publications (e.g. for coordinates) but also discriminant enough to not match irrelevant items. For instance, the regular expression about soil texture catches a lot of terms related to soil texture but not all were related to the soil texture of the actual field site. Applying regular expression on specific parts of the manuscript (for instance, just on the material and methods section), could help improve the precision of the technique.
In addition, information about precipitation, soil texture or applied tensions can be provided in tables. But extracting information from these PDF tables is complex. Indeed, the PDF format does not encode the table as a table but rather as a series of short paragraph and vertical/horizontal lines placed at a given position. When converting the PDF to text, only streams of numbers with more or less regular spacing are found and rebuilding a logical table from it is challenging. Analyzing the regularity of the spacing between these numbers can help in some cases in rebuilding the tables (e.g. Rastan (2019)) but nevertheless understanding what these numbers represent based solely on the headers is for now out of reach of the NLP algorithm. However, recent publications are often provided as an HTML version in which the tables are actually encoded as HTML tables or provided as separate .xlsx, .csv files, hence enabling easier information extraction.
Another difficulty of the conversion from PDF to text is due to the layout of many scientific journals. Text boxes and figures can span multiple text columns and make the conversion difficult (e.g. the figure caption intercalated in the middle of the text). This led Ramakrishnan (2012) to develop LA-PDFText, a Layout Aware PDF to text translator designed for scientific publication. The addition of a hidden machine-friendly text layer in the PDF itself could help the NLP algorithm to better extract information from this format.
Relationship extraction¶
Relationship extraction based on abstract provides a quick overview of the conclusions from a given set of documents (Figure 10). The identification of statements related to a given pair of drivers/variables can already provide some information about potential knowledge gaps (Figure 8). However, one important limitation of the approach is that the algorithm can only find the keywords it was told to look for. For instance, no social drivers were found in the statements as there were no keywords associated with it. Social drivers are important to estimate the acceptability of management practices (Chapter 3) and they would gain to be included in the workflow. Another limitation is the fact that the algorithm is limited to what is written in the text. For instance, in Figure 8, the token ‘k’, ‘Ks’ and ‘hydraulic conductivity’, all associated with hydraulic conductivity are all extracted by the NLP algorithm as they appear in this form in the abstracts. The use of synonyms can help associate tokens with similar meaning.
The classification of the extracted relationships remains a challenging task and a lot of statements just mention that the pair of drivers/variables has been studied but not the outcome of it (Figure 9). That is one of the limitations of the approach as not all information is contained in the abstract. Applying this technique on the conclusion part of a manuscript could help complement the relationships found.
In addition, to confirm that the relationships extracted are well classified a labeled dataset is needed. For this purpose, one has to manually label a given proportion of the statements found and then compare the labels with the NLP finding and iteratively improve the NLP algorithm. This procedure is tedious but needed as general relationships algorithms (often trained on newspaper articles or wikipedia) failed to extract meaningful relationships from field-specific scientific publications. Indeed, a custom NLP algorithm trained on the specific sentence structure and vocabulary encountered in abstracts is more suited to the task. This is in agreement with the conclusions of Furey (2019). However, despite our efforts, the complexity of certain sentences (long sentences with comparison and relative clauses) was too high for our algorithm to reliably detect the relationships between a driver and a variable.
The use of more advanced methods that convert sentences to vectors by the use of transformer networks (e.g. BERT, Koroteev (2021)) can help convert sentences into a numerical vector that carries information about the context of the sentence. Feeded to a deep learning algorithm, these could then provide a deeper understanding of the meaning of the sentence. However, to achieve this larger amount of labeled data will be needed. While a deep understanding of the sentence can certainly help in better classifying drivers/variables relationships, simple regular expressions have already proven to be useful to retrieve specific metadata.
Conclusion¶
With the growing body of environmental scientific literature, NLP techniques can help support the needed evidence synthesis. In this work we present examples of three different NLP techniques that can be used for extracting structured information from a large corpus of scientific publications in the domain of environmental sciences. Topic modeling helps to classify existing documents into subtopics and identify less researched topics. It can also be used to assign a new document to a given topic. Both are useful for evidence synthesis. Simple regular expressions helped to retrieve specific information from a corpus of papers on tension.disk infiltrometer measurements, such as coordinates, rainfall, soil types and texture, tension-disk diameter and tensions applied. This technique can be used to build up databases or for evidence synthesis. However, the conversion from the PDF format to text can be a source of mistakes given the complex layout of scientific articles and the non-machine friendly PDF format. While PDF remains a standard, web versions of scientific manuscripts have the potential to relieve this barrier. Finally, based on abstracts, sentences containing a given pair of drivers/variables were identified. The number of relationships identified per pair already provides an insight into what topics are best studied and can be used to identify knowledge gaps. The list of drivers and variables need to be expanded iteratively to be sure that all synonyms can be caught. Using the shortest dependency path between a driver and a variable, their relationship was classified into negative, neutral, positive or ‘study’ (if it was just mentioned that the topic is studied in the paper). While their classification remains challenging and field-specific given the complexity of human language, this approach can already provide a good overview of the main conclusions drawn from a corpus of documents. Overall, topic modeling, regular expression and complex relationships extraction have the potential to support fully automated evidence synthesis that can be continuously updated as new publications become available.
- Haddaway, N. R., Callaghan, M. W., Collins, A. M., Lamb, W. F., Minx, J. C., Thomas, J., & John, D. (2020). On the use of computer-assistance to facilitate systematic mapping. Campbell Systematic Reviews, 16(4), e1129. 10.1002/cl2.1129
- Hirschberg, J., & Manning, C. D. (2019). Advances in natural language processing. ARTIFICIAL INTELLIGENCE, 7.
- Nadkarni, P. M., Ohno-Machado, L., & Chapman, W. W. (2011). Natural language processing: an introduction. Journal of the American Medical Informatics Association, 18(5), 544–551. 10.1136/amiajnl-2011-000464
- Nasar, Z., Jaffry, S. W., & Malik, M. K. (2018). Information extraction from scientific articles: a survey. Scientometrics, 117(3), 1931–1990. 10.1007/s11192-018-2921-5
- Wang, Y., Wang, L., Rastegar-Mojarad, M., Moon, S., Shen, F., Afzal, N., Liu, S., Zeng, Y., Mehrabi, S., Sohn, S., & Liu, H. (2018). Clinical information extraction applications: A literature review. Journal of Biomedical Informatics, 77, 34–49. 10.1016/j.jbi.2017.11.011